
Based on the previous post we did in which we made an introduction on #DeepLearning, we continue now presenting the typical network architecture used nowadays to solve the three main tasks of deep learning in image processing: image classification, object detection and image segmentation.
1. Convolutional Neural Networks (CNNs)

1: Example of CNN applied on medical image, [2].
CNNs or ConvNets are feed-forward neural networks that use a spatial-invariance trick to efficiently learn local patterns in images. As discussed in previous post, CNNs share weights across the layers in the network to precisely detect or extract the targeted features on the training images.
These networks used convolutional layers, which apply mathematical convolutions on the input image as shown here:
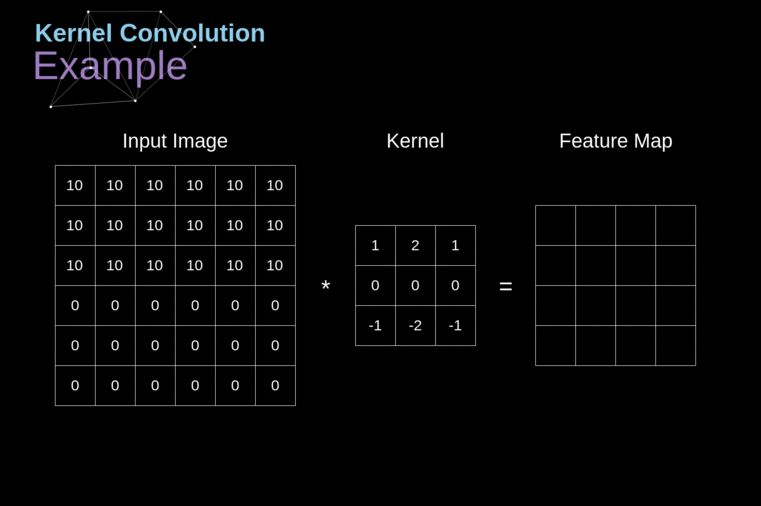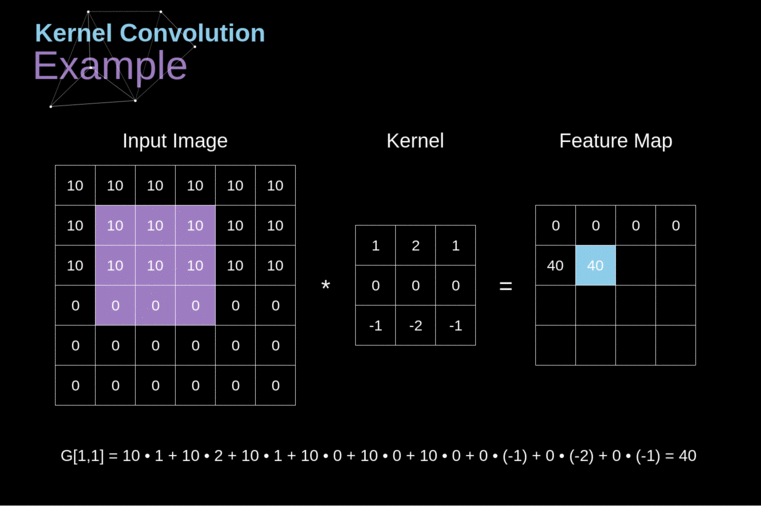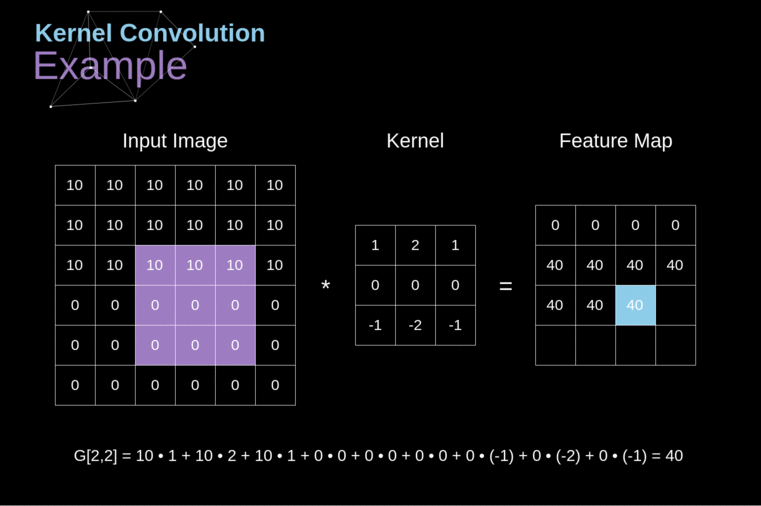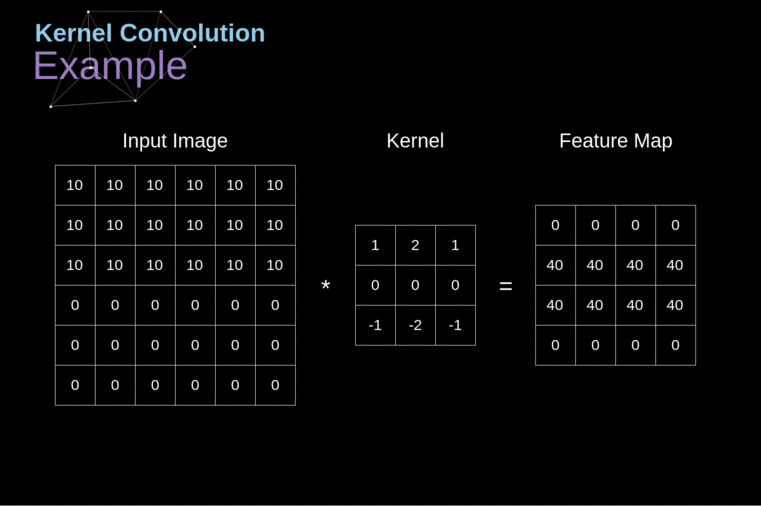
2: Example of convolution[3]
These networks are used for image classification, object detection, video action recognition, and any data that has some spatial invariance in its structure (e.g., speech audio).
Example of #CNN applied on digit identification on typical MNIST dataset [1]:

2. Recurrent Neural Networks (RNNs)

Recurrent Neural Network remembers the past and its decisions are influenced by what it has learnt from the past [1].
These network architectures are widely used in speech or handwriting recognition. While in typical NN architectures each layer is influenced only by its inputs multiplied by the weights, in the RNNs each layer is influenced by its input plus the output of the layer in the previous instant. This leads to this NNs having a temporal dynamic behavior.
The idea behind RNNs is to make use of sequential information. RNNs are called recurrent because they perform the same task for every element of a sequence
This architectures are typically used for image classification tasks.
3. Generative Adversarial Networks (GANs)

Generative Adversarial networks or GANs a framework for training networks that aim to generate realistic samples. This framework has two main networks: a generator (G) and a discriminator (D). The process begins with an extraction of the samples from the training images. The job of the generator will be to create similar samples as theses ones and “fool” the discriminator, which has to determine whether the generated sample by G is real or fake.
The generator G is typically fed by gaussian noise and this is transformed iteration by iteration into samples similar as the ones extracted from the training set. The training ends once a big percentage of generated samples have fooled the discriminator D.
GANs are widely used nowadays, but maybe one of their mostly known applications is #DeepFake, technology in which characters in videos have their face swapped with other character’s or person’s face, integrating the gestures and movements from the original face into the new one. Here an example:

3: Example of DeepFake on a film sequence, [4].
REFERENCES: